
Struct Layout Basics
When you define a struct, you indicate which fields the struct contains:
public struct Point
{
public float X;
public float Y;
}
This is sometimes done with properties, and some properties, such as auto-properties, will create fields behind the scenes for you. The following still has two fields; they’re just “hidden” behind the auto-properties:
public struct Point
{
public float X { get; }
public float Y { get; }
}
Everything we’re going to cover here applies equally well to the backing fields of auto-properties, but for simplicity, we’ll use structs with bare fields.
When you declare a variable (or an array, which you can think of as just many variables back to back) with the type Point, a single, contiguous block of memory is reserved for your Point value.
But what exactly does that memory look like? The way a struct’s fields are arranged in memory is referred to as layout.
The C# language and the compiler don’t really care how this is done. They both generally leave this decision to the runtime, which will need to make some layout decisions to make the rubber meet the road.
By default, the runtime is given a fair bit of latitude to make its own layout decisions. (In a future post, we’ll look at how you can give the runtime more precise instructions on laying out a struct.)
One consequence of this latitude is that what happens may vary between operating systems (Windows vs. Linux), hardware architectures (x86 vs. ARM), and even runtime implementations (.NET Framework vs. the newer .NET).
On paper, this means that our humble Point struct could end up reserving two thousand bytes for a single Point, putting the four bytes needed for Y right at the beginning and the four bytes needed for X right at the end, and have a 1992 byte gap in the middle.
In theory. In practice, nobody in their right mind is going to do that. I say this because I’m going to show you what my computer is doing. It is probably the same thing your computer will do, but I can’t guarantee it.
Our Point struct has two fields: X and Y.
Each use the float type, and the float type needs 4 bytes.
So a reasonable layout for this struct would be to reserve 8 bytes and put X in the first four bytes and Y in the next four bytes, like this:
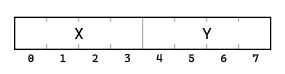
And you’d be right! That’s how the runtime (at least on my computer) lays out the memory for that struct.
What about this one?
public struct FloatAndFourBools
{
public float A;
public bool B;
public bool C;
public bool D;
public bool E;
}
A float is 4 bytes and a bool is 1, so you might think the following layout is what you’d get:
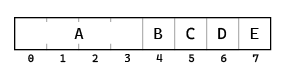
Indeed, that is what the runtime seems to be doing for me.
What about this one?
public struct BoolAndFloat
{
public bool A;
public float B;
}
You might think you’d get this arrangement:
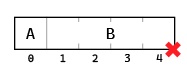
But that’s not what it does. Instead, I got this:
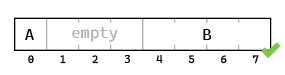
It added three bytes of nothing right in the middle! These empty bytes are called padding. They’re added because of how the hardware works.
The CPU and RAM are often built in a way that is optimized for working with data in chunks bigger than a single byte.
For example, many are optimized to work with 4-byte or 8-byte chunks, called a word.
After all, on 32-bit and 64-bit computers, that is the size of the registers and the main bus that pushes data around through the CPU.
If a float value spans two of these chunks, the CPU may need to perform two reads and patch together the actual value from the bytes spread across the two chunks.
In these cases, it is often worth using a few extra bytes to ensure our data is aligned to these boundaries. In this particular case, that is what the runtime has opted to do: spend a few extra bytes to ensure our fields don’t span these boundaries unnecessarily.
The key takeaway is that your structs may be bigger than you would normally expect because the runtime might be adding in padding bytes to keep things aligned with what the hardware itself can work with efficiently.
We’ve only scratched the surface, and I plan on writing more blog posts about this in future. Stay tuned!